The biggest problem you would have processing multiple channels is currently Audulus only supports two channels when used as an AU/VST. In order to use more than two channels in a single instance of Audulus, it would be necessary to run Audulus in stand-alone mode. This is potentially possible in the macOS environment using SoundFlower. but probably isn’t the best solution.
Probably the best way to implement this is using a set of compressors with side chain inputs. You create a send bus with the sum of the uncompressed signals from each channel and use the output of this bus to control a compressor on each channel. You then mix the compressed outputs together. This way you limit the output of the mix.
It is certainly possible to build a compressor using Audulus, and there are several examples posted on the forum. You might find this one of some use: Moonwalk - a compressor to pump your kicks
I never figured out the secret sauce for the Dugan automixer, but when I worked at a news station I created a routing configuration that worked similarly for a talking head show.
I had four speakers, so I made four buses with compressors and sent all the mics except for the person speaking to the sidechain of the coompressor for that channel.
So the sidechain of channel 1 compressor would be fed signal from channels 2,3,4. The sidechain of channel 2 compressor was fed signal from channels 1,3,4. And so on. This way when one person talks, it compresses every one else’s mic down.
This also has the benefit (if you use aux sends) of being able to send more or less of a channel depending on the importance of the person. For example, the host would be able to talk over every one else.
Having said all that, I didn’t have Audulus at the time. Gain sharing could be done in a completely different way…
I think your approach is essentially the same as the Dugan method, at least if I’m understanding the article. It would certainly be more effective if you didn’t send the signal from mic 1 back via the sidechain to the compressor on mic 1. It does mean a separate send bus for each channel, but that’s not a big deal. It got me playing around with routing in Ableton. I recently switched from Reaper (mostly anyway) and Ableton’s approach to routing is quite a bit different. Between racks, groups, track I/O and send tracks there are a lot of different options.
It would be nice if the Audulus AU supported multi-channel I/O. Maybe we’ll see it in A4.
I am definitely trying to achieve the Dugan method. My thought initially was that I was going to need Sound Flower, along with the stand alone Audulus. It is not ideal but is better than using the sound mixer method I am currently using. Audio out of the DAW, into the mixer, out of the mixer, and back into the DAW. Routing audio in the box with sound flower is one step closer. Though not ideal simply because it cannot render the audio in accelerated time.
Based on your most recent response, are you saying a sudo Dugan auto mixer is possible within in DAW with stock plug-ins (without Audulus)? Im trying to understand your thoughts on signal flow. My current DAW is Logic Pro X.
I think SteveX described the most practical approach in his post above. Say we have mic channels 1, 2, 3, and 4. Create a bus for each channel and route the other channels to the bus pre-FX. So we would route 2, 3, and 4 to the channel 1 bus, 1, 3, and 4 to the channel 2 bus etc. That means each bus has a signal equivalent to the sum of all channels minus the bus channel, i.e.[ sum(Ln) - Ln]. By connecting the signal from the channel 1 bus to the side-chain input of a compressor on channel 1 you will effectively reduce the post compressor gain of channel 1 based on the signal from channels 2, 3 and 4. You also control the gain of the other channels in a similar fashion. The orginal Dugan approach actually uses an individual level detector for each channel and one for the sum of the outputs, rather than subtracting the raw signal but for uncorrelated signals I don’t think it will make a huge difference. To actually reproduce the algorithm in its entirety you would need to design an appropriate level detector. According to his patent, Dugan uses a log envelope follower which can certainly be built in Audulus. The real trick is determining the proper time constants to use within the envelope followers and VCAs so that you get a smooth response with no “pumping”.
I put together this compressor a while back which uses a peak detector style of envelope follower that could be used as a basis for for a practical envelope follower unit: compressor V1.1.audulus (138.0 KB)
The one difference I couldn’t figure out between his algorithm and my routing was how he kept his noise floor consistent. If no one is talking in the setup I had, all microphones were on fully. In his algorithm, all of the mics on would have the same noise floor as just one open mic.
There’s a video of him explaining this somewhere. He also states that there’s no threshold or gating applied, so it’s definitely different to how I had done it.
Anyways, I ended up having the studio buy his automixer. It was way better.
If you need a head start to a level detector, you can pull apart one of my compressors. That’s essentially what they are.
Dugan’s algorithm will increase the gain of the mic with signal and decrease the gain of the other channels. If Ln is greater than the sum(Ln) component, the expression [sum(Ln)-Ln] becomes negative so that Ln - [sum(Ln)-Ln] will be greater than L(n). This results from the fact that the sum(Ln) component is the level of the summed signals rather than the sum of the levels of the signals. Since the levels are log values the subtraction is essentially calculating the ratio between the level of the mic and the level of all the mics summed. When no signal is present, the gain of each channel is such that the noise floor is approximately equal to one mic at full gain. As the level of one mic is increased all the others go down. Your routing can only decrease the gain of a channel since it uses compressors to control the gain. There is a pretty good description at:
I used an asymmetric peak detector for my compressor. I couldn’t figure out any practical way to calculate an RMS value since we don’t have any storage, so I used a log based envelope follower feeding a filter with adjustable attack and release values. I see that your Moonwalk unit uses a similar approach. I didn’t include a side-chain input on mine, but I probably should have. I think it would be possible to build a Dugan auto mix in Audulus, although I think your scheme is probably a more practical approach.
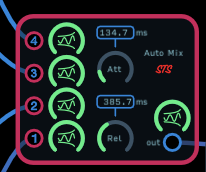
Here’s my attempt to implement the Dugan algorithm:
It has 4 channels, an adjustable attack and release for the level detectors and adjustable pads for the inputs and output. All the way up is unity gain and they have an exponential response. I couldn’t test it very thoroughly, but it seems to work. There are a couple of parameters internally that might need to be fine tuned. There is a pad after the adjustable one for each channel that reduces the signal fed from each channel to the summing level detector. It’s currently set at 0.421 (-7.5 dB), and there is a similar pad value that’s subtracted from the VCA gain before the channels are mixed. It’s currently set at 6.0 dB. These values are reasonable for 4 channels, but might need to be altered if you add additional channels Auto Mix V1.2.audulus (150.7 KB)
FYI, I did a bit more fine tuning. If you grabbed V1.1, I’ve changed the internal pads to 0.421 (-7.5 dB) and 6.0 dB in V1.2. Also the demo oscillator for channel 3 wasn’t connected
FYI this version of the Dugan mixing algorithm was designed for speech applications where multiple mikes are present. It raises the gain of the mike currently in use and lowers the gain of the other mics. Because it continuously changes the balance between the mics, it is not actually very useful for musical applications. Dugan also designed several units for musical mixing, but they used a different approach. Traditional compression is probably a better bet if you’re just trying to get some additional headroom.